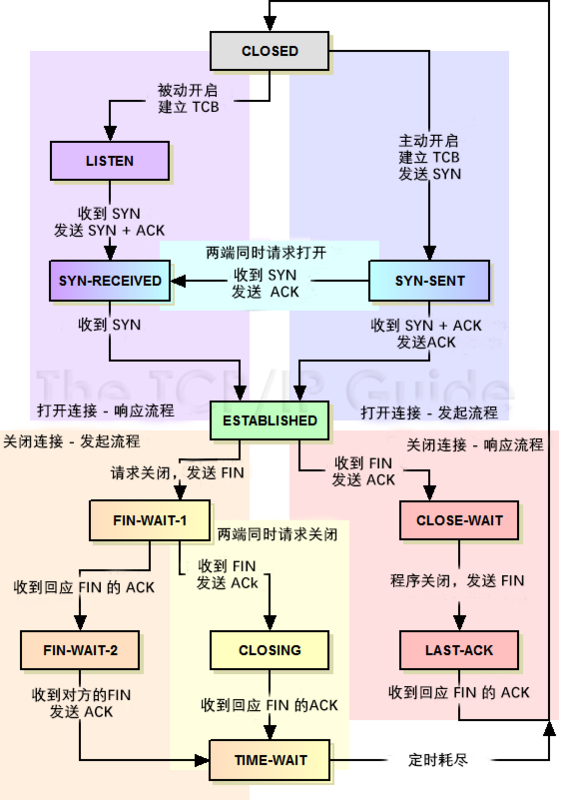
TCP 连接的建立与关闭
tcp(Transmission Control Protocol) 是一种位于传输层、面向字节流、保证可靠传输的全双工协议,作为底层协议,支撑着着应用层如 http、SMTP 等。鼎鼎大名的 三次握手、四次挥手指的就是其建立与关闭的流程。
tcp 协议的生命周期,本质是一个有限状态机 的流转,从建立到数据传输再到关闭,伴随着不同状态的迁移。而在不同的状态中,又会有着一些优化与问题。
tcp 协议 本身极其复杂,除了建立与关闭涉及到多次交互外,还需要考虑 差错检测、滑动窗口、重传策略、拥塞控制、RTT(Round Trip Time)、MSS(maximum segment size) 等等,远古大神们真是费煞苦心。
注:本文的图例来自网络,历史原因未标明出处,感谢原作者们清晰的图示 :)
首部结构
tcp 报文首部格式如下:
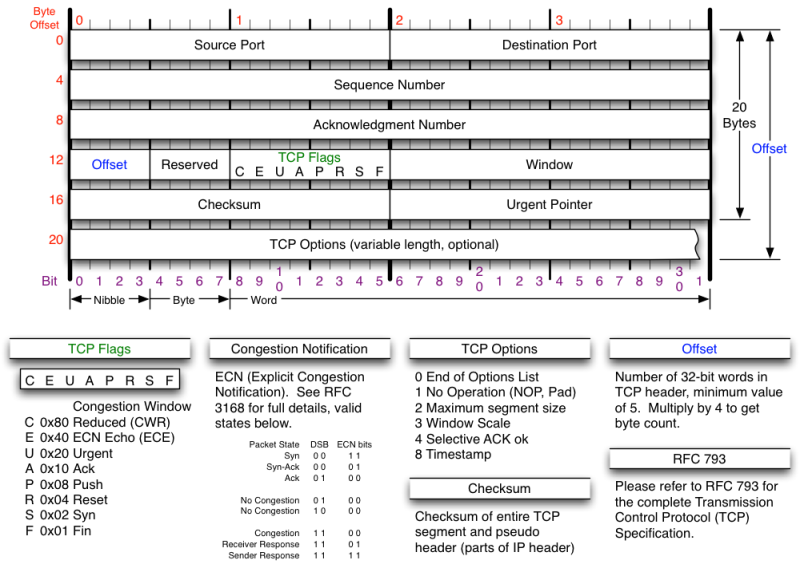
其中,在日常分析 tcp 的建立与关闭时,主要关注的是在 FLAGS 字段,该字段也即所谓的 tcp 状态机,主要有如下字段(大写表示,与序列号区分开):
SYN:Synchronize,表示建立连接。FIN:Finish,表示关闭连接。ACK:Acknowledge,表示确认。PSH:Push,表示当前正在传输数据RST:Reset,表示连接重置,一方可以主动发送该状态断开连接。
然后,有两个重要的 32位 序列号:
-
seq:Sequence number,表示序列号,用来保证数据的有序传输。- 如果
SYN设置为1,其表示ISN(initial sequence number),也即,初始序列号,并期望对方能返回该ISN+1的ack。 - 如果
SYN设置为0,表示当前传输报文段中首字节的编号(在当前全部字节流中,通过mss分段后的编号。
- 如果
-
ack:Acknowledgment number (if ACK set)- 当且仅当
ACK设置为1时,才有效。 - 表示期望收到的下一个
seq,如果是SYN的ACK,其值为发起方的ISN+1。
- 当且仅当
建立
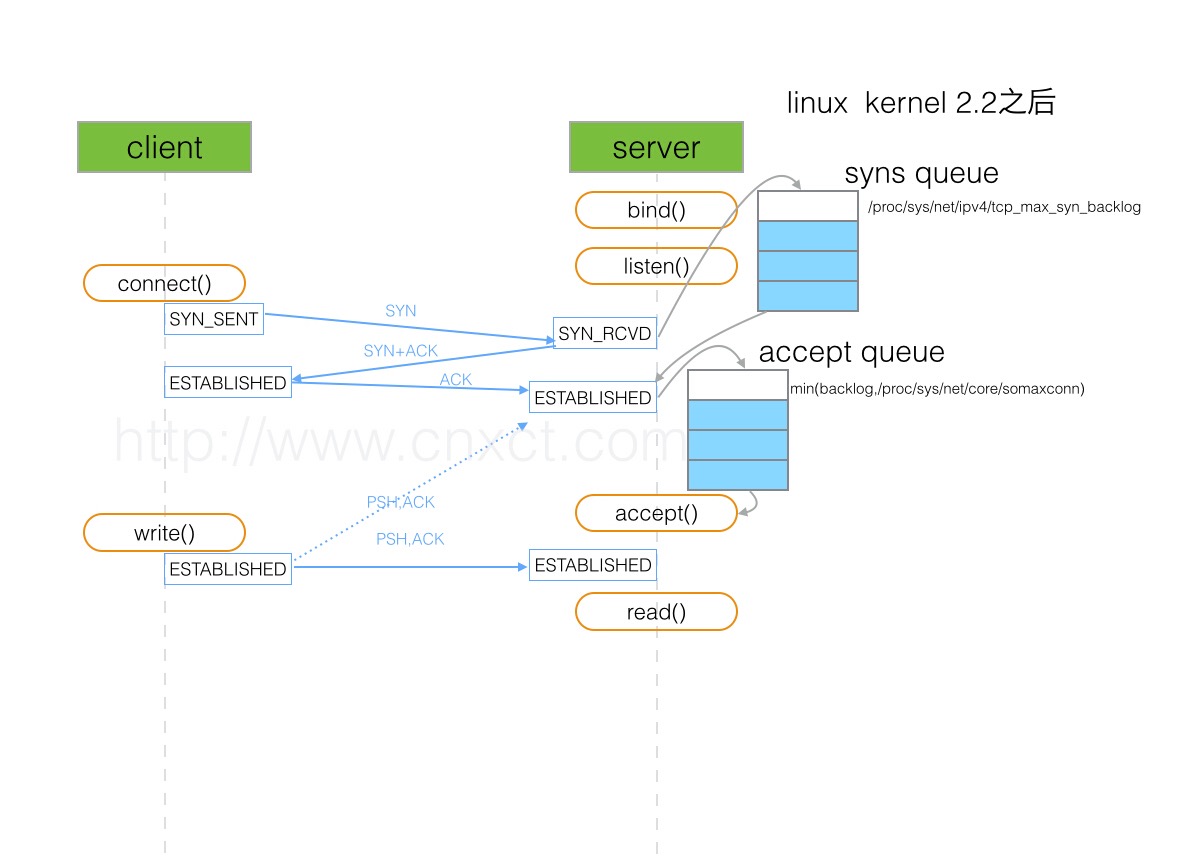
我们使用 client 表示主动发起建立方,server 表示被动响应建立方,server 需要 bind 某个端口并 listen,做好随时迎接一个连接的准备。
一个连接的建立,大体流程如下:
- 1、
client发送请求建立连接的报文,其中SYN = 1,seq为一个随机值ISN1,注意这里必须是随机值而不能设为1,防止被猜测序列号后恶意攻击(也即所谓的「TCP序列猜测攻击」)。- 此时,
client进入SYN_SENT状态。
- 此时,
- 2、
server收到请求报文后,发送一个SYNC = 1, ACK = 1,也即SYN+ACK,且同样的,随机一个ISN2作为seq,并设ack = ISN1+1,也即对请求报文的确认。其中ack表示希望client接下来传该字节开始的数据流。- 此时,
server进入SYN_RECEIVED状态。
- 此时,
- 3、
client收到响应报文后,需要再次确认,发送一个ACK = 1,并设ack = ISN2+1,seq = ISN1+1,也即表示自己收到了server的确认报文。这里,seq = ISN1+1是因为,从语义上来说,server希望收到该序号的报文。- 此时,
client进入ESTABLISHED状态,server在收到ACK后也进入ESTABLISHED状态。
- 此时,
自此,我们可以认为双方进入 ESTABLISHED 状态,全双工连接建立完成。但其实,这里准确的说,应该是 client 进入了 ESTABLISHED 状态,server 是否成功还取决于当前 accept queue 的情况,下面会具体分析。
需要注意的是,上面的流程中,并没有真正的发送数据(最后一次握手客户端可以携带数据),双方只是进行一系列序列号交换的握手操作。
整体示意图如下:
为什么是三次握手
为什么是三次握手,而不是不是2 次或4 次呢?
从建立的流程可以看出,第一次 发送,表示 client 请求建立连接;第二次表示 server 收到了请求并做了回复。这里如果没有第三次就 ESTABLISHED 了,开始传输数据,那么会有什么问题呢?
这里,我们需要重点关注 seq ,tcp 就是依据这个字段进行所谓 可靠传输 的,也即,tcp 双方都依赖这个序列号来进行数据包的有序传输。从语义上来说,参与 TCP 连接的双方,都需要满足:
- 知道对方下一个要发的包序列(对方
seq) - 知道对方收到了自己之前发出的包(我方
seq)
所以,在前两次握手完成后,双方都进入 ESTABLISHED,此时:
-
client得到了正确的返回ISN1+1,且得到了server的seq,也即cient知道server已经收到自己的数据包了,且知道server下一个要发的序列; -
server不确定自己的ACK是否成功被client接收,假设这时这个包丢了,此时,client不知道server的seq,server就无法保证client是按照正确的顺序来接收自己的数据包。也即,如果server继续发送数据,client无法做到有序接收。
以上,不满足 TCP 的语义要求。
另外,还有其他场景,如:
-
client先后发送了两次SYN,第一个SYN延时了,第二个SYN先行到达server; -
此后双方基于第二个
SYN建立了连接,传输数据,关闭连接; -
这时,延时的第一个
SYN又到了server,然后server回复ACK,又进入了ESTABLISHED。但这时client不会接收这个ACK,更不会发送数据了,所以导致server一直处于等待数据传输状态,直至被内核关闭。 -
而如果使用
三次握手机制,此时server收不到client的ACK,也不会建立连接。
为什么不是 4 次握手 呢,因为 TCP 协议允许同时发送 ACK + SYN,也即握手的第二步。然后通过以上分析,这里我们已经知道最少需要 3 次就已经可以建立了,所以,为什么还要多一次呢,浪费资源 。。。
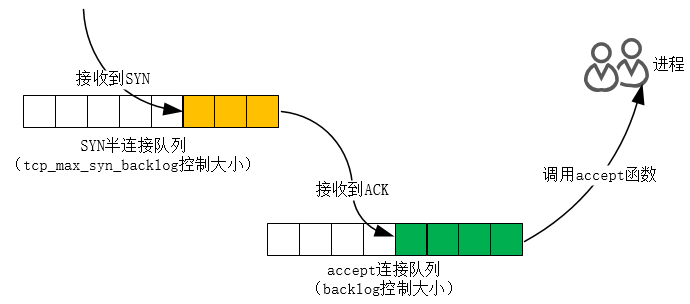
backlog 是什么
在上面的示意图中,我们可以看到,server 端有两个 queue:syn queue、accept queue,其含义为:
-
syn queue:半连接队列(Half-open Connection)。当server收到SYN报文后(>=1个),内核需要维护这些连接,所以需要一个队列保存下来,也即这里的syn queue,同时发送SYN+ACK给client。-
队列未满:加入到
sync queue。 -
队列已满:如果
net.ipv4.tcp_syncookies = 0,直接丢弃这个包,如果设置了该参数,则:-
如果
accept queue也已经满了,并且qlen_young的值大于 1,丢弃这个SYN;其中,qlen_young表示目前syn queue中,没有进行SYN+ACK包重传的连接数量。 -
否则,生成
syncookie并返回SYN+ACK。
-
-
可构造
TCP SYN FLOOD攻击,发送大量的SYN报文,然后丢弃,导致server的该队列一直处于满负荷状态,无法处理其他正常的请求。
-
-
accept queue:全连接队列。当server再次收到client的ACK后,这时,如果:-
队列未满:将该连接放入到全连接队列中,系统调用
accept本质就是从该队列不断获取已经连接好的请求。 -
队列已满:取决于
tcp_abort_on_overflow的配置-
tcp_abort_on_overflow = 0:server丢弃该ACK,再由一个定时器net.ipv4.tcp_synack_retries重传SYN+ACK,总次数不超过/proc/sys/net/ipv4/tcp_synack_retries配置的次数。 -
这是因为此时
server还处于SYN_RECEIVED状态,所以再次发送报文告诉client可以重新尝试建立连接(可能server下一次收到该包时队列变成未满状态了 )。此时,若client的超时时间较短,则表现为READ_TIMEOUT,因为client已经处于ESTABLISHED了。 -
tcp_abort_on_overflow = 1:server回复RST,并从半连接队列中删除,client表现为Connection reset by peer
-
-
这里的逻辑比较复杂,涉及到内核很多参数的设置,具体可以参考相关书籍,下面是更清晰的图示:
我们回到标题的 backlog 上,之所以重点关注这个参数,是因为在日常的 web 开发 中,涉及到的 nginx + redis + php-fpm 等,配置项大多都有这个参数,而这些软件都是典型的 server-client 结构。
server 监听函数 listen 原型如下(man listen),这里第二个参数就是我们要讨论的 backlog:
|
|
这个 backlog 参数,定义是 已连接但未进行 accept 处理的 SOCKET 队列大小,也即上面提到的 accept queue。如果这个队列满了,将会发送一个 errno = ECONNREFUSED 的错误,即 linux 头文件 /usr/include/asm-generic/errno.h 中定义的 Connection refused。
接下来分别看下常用软件的设置:
nginx:默认为511
|
|
redis:默认为511
|
|
php-fpm:默认为511
|
|
所以,我们 惊奇 的发现,三者的默认值都为 511,但其实之前 php-fpm 设置的是 65535,后来在某个版本中 fix 了,issue 参见 Set FPM_BACKLOG_DEFAULT to 511。
那么,为什么要 fix 这个数值呢,我们可做如下推理:
-
如果
php-fpm的backlog过大,通过nginx的请求可以一直建立,但如果php的处理速度变慢了,后面的连接执行时间过长,可能超出了nginx的fastcgi_read_timeout设置,fpm往这个socketwrite时,nginx已经断开了连接了, 会出现broken pipe错误,也即Connection timed out,nginx表现为504 Gateway Timeout -
如果
php-fpm的backlog过小,nginx的请求超过fastcgi_connect_timeout时间还未建立,,也即Connection refused,nginx表现为502 Bad Gateway错误。
所以, php-fpm 的就设置为 nginx 一样,511,因为内核源码的判断条件是 >,因而这些常见的应用最多能 accept 512 个请求。
KeepAlive
也即 keep TCP alive,因为 TCP 本质是基于 传输层 建立的连接,对 链路层 而言,只是,很多硬件设备会主动断开不活跃的连接,比如几大运营商、一些中间网络设备、甚至代理服务器等,都会主动 drop 一定时间不活跃的链接。
比如 nginx,默认 75s 关闭连接,但这里是基于 http keep alive 设置的:
|
|
此外,而且上层程序也需要对当前的连接进行探活,下面看 reids 的相关配置:
|
|
也即,对于 redis 来说,为了避免太多空闲的 client,最大化利用性能
关闭
我们使用 client 表示主动发起关闭方,server 表示被动响应关闭方。
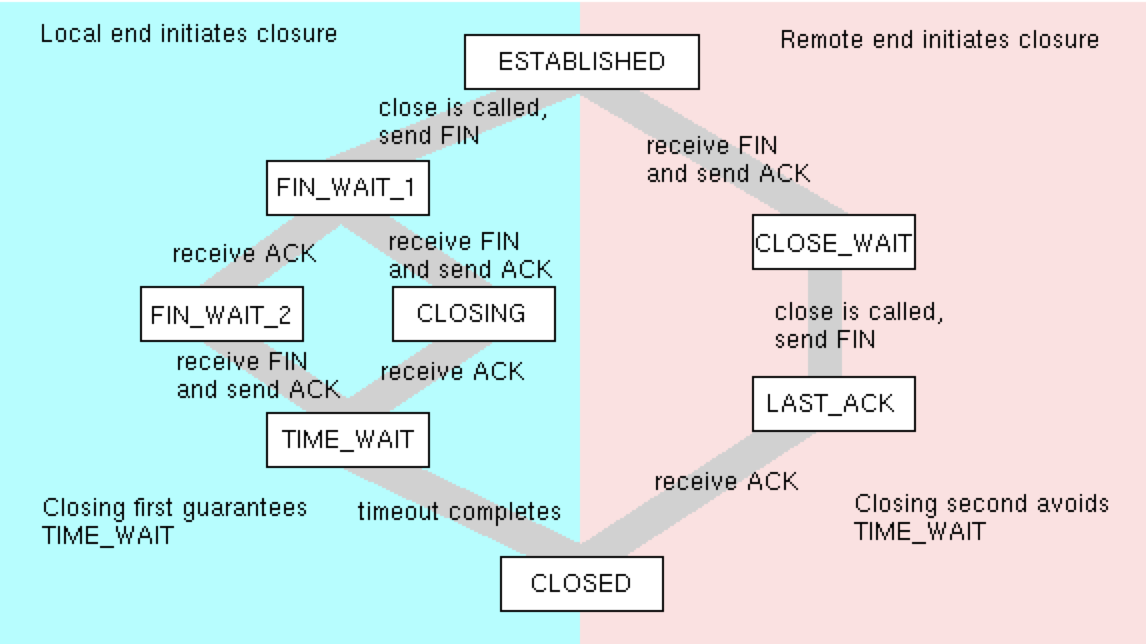
四次挥手
关闭一个 TCP 连接,大致流程如下:
-
1、
client调用close发送请求关闭连接的FIN报文,此后,client进入FIN_WAIT_1状态。 -
2、
server收到FIN报文后,内核自动回复ACK,然后连接进入CLOSE_WAIT状态。该状态表示该连接正在等待进程调用close关闭,此时,进程可能还有别的事情要处理。client收到ACK后,进入FIN_WAIT_2状态,表示等待server主动关闭连接。此时,实际上client的发送通道已经关闭了,但连接还未关闭。
-
3、当
server进入CLOSE_WAIT状态时,进程继续read时会返回0,通常的处理逻辑是在这个if (read() == 0)下调用close,触发内核发送FIN报文,此时状态变为LAST_ACK。 -
4、
client收到这个FIN后,内核会自动回复ACK,然后连接进入TIME_WAIT状态,然后继续等待2MSL后关闭连接。server收到ACK后,关闭连接,至此,双方都成功关闭。
大体流程如下:
|
|
这里,需要强调的是:
-
TCP必须保证报文是有序发送的,FIN报文也需要遵循这个规则,当发送缓冲区还有数据没发送时,FIN报文不能提前发送。 -
如果是调用
close 函数主动关闭,处于FIN_WAIT_1或FIN_WAIT_2状态下的连接,则会成为孤儿连接,通过netstat -anp | grep -i fin查看,是看不到进程相关信息的。这时,即便对方继续传输数据,进程也接收不到了。也即,这个连接已经和之前所属的进程无关了。 -
如果是调用
shutdown 函数主动关闭,TCP允许在半关闭的连接上长时间传输数据,处于FIN_WAIT_1或FIN_WAIT_2状态下的连接,不是孤儿连接,进程仍然可以继续接收数据。 -
存在一种特殊情况:被动关闭方收到
FIN后立即调用close,那么可能会发出一个ACK+FIN报文,这样就会少一次挥手。 -
如果双方同时
close,双方都认为自己是主动关闭方,都进入了FIN_WAIT_1,然后都得到了对方的FIN,此时双方会进入CLOSING状态,该状态同LAST_ACK情况相似。
参数调优
主动关闭方
看完上面的流程,针对主动关闭方,就会有些疑问了,比如,假设 client 一直没收到 ACK 怎么办,会一直处于 FIN_WAIT_1 状态吗?client 处于 TIME_WAIT 后如何处理?server 到底什么时候真正关闭连接?
下面逐个状态具体分析。
FIN_WAIT_1
如果 client 一直没收到 ACK,也就会一直处于 FIN_WAIT_1 状态。此时,内核会根据 net.ipv4.tcp_orphan_retries 的配置定时重发 FIN,直至重试失败,直接关闭。该参数会对所有处于 FIN_WAIT_1 的连接生效,不仅仅是 孤儿连接,默认重试发送 8 次,也即如果没收到 ACK,主动关闭方会发送 9 次 FIN !至于这个定时时间是多久,取决于当前的 RTO,一般是经过采样然后加权计算出来的。
|
|
所以,如果服务器有大量的 FIN_WAIT_1,可以考虑减少 net.ipv4.tcp_orphan_retries 的值,避免过多的重试。
在 FIN_WAIT_1 状态下,还有一个很重要的参数:net.ipv4.tcp_max_orphans,用来控制系统所维持的该状态下连接数的最大值。如果孤儿连接数量大于该值,新增的孤儿连接将不再走四次挥手过程,而是直接发送 RST 报文强制关闭该连接。
该参数主要是用来防范恶意攻击,比如攻击者恶意构造 接收窗口为 0 的报文,因为 TCP 的流量控制策略,此时不能继续发送数据了,导致 FIN 无法发送,然后越来越多的连接一直处于 FIN_WAIT_1 状态,最终系统不可用。
FIN_WAIT_2
前面已经提到,shutdown、close 的关闭模式不一样,前者关闭,连接可以一直处于 FIN_WAIT_2 状态了;而 close 下的关闭,这个状态不能存在太久,取决于 net.ipv4.tcp_fin_timeout 参数的配置,其实这个参数控制的就是有名的 MSL。如果一直没收到对端发送的 FIN,在超过这个时间后, 这个连接会被直接关闭。
TIME_WAIT
从四次挥手的过程,可以知道,client 收到 server 的 FIN 后,进入 TIME_WAIT,然后需要等待 2MSL 也即 2 * net.ipv4.tcp_fin_timeout 时间,再关闭连接。
为什么要等 2MSL 这么多时间呢?
从 server 的视角去看,发送 FIN 后,连接处于 LAST_ACK 状态,等待 client 的 ACK,再关闭连接。如果这个 ACK 没有到达,同样的,server 会根据 net.ipv4.tcp_orphan_retries 的配置定时重发,直至收到 ACK 或重试次数到达上限,再关闭该连接。
如果 client在发送 ACK 后就关闭连接,释放的端口可能被复用于新的连接,但上面提到,server 可能会重发 FIN,就干扰了新建的连接。所以需要在 TIME_WAIT 下保留一段时间,防止 server 的 FIN 重发,以及其他可能的数据重发,避免数据错乱。
至于为什么是 2 倍 的 MSL,而不是更多倍呢,这就是在设计时的一种平衡了。2MSL 下,允许对方重发一次,而如果超过 2 次都丢弃了,说明网络本身状况很糟糕,与其继续等待,不如主动关闭。所以与 FIN_WAIT_2 一样,都会在该状态下保存 2MSL 的时长。
|
|
linux 下,提供了 net.ipv4.tcp_max_tw_buckets 参数来控制 TIME_WAIT 的连接数量,超过后,新关闭的连接就不再走 TIME_WAIT 阶段,而是直接关闭。如果服务器的并发连接增多时,TIME_WAIT 状态的连接数也会变多,此时就应当调大 tcp_max_tw_buckets,减少不同连接间数据错乱的概率。因为系统的内存和端口号都是有限的,还可以让新连接复用 TIME_WAIT 状态的端口,配置 net.ipv4.tcp_tw_reuse = 1,同时需要双方都把 net.ipv4.tcp_timestamps = 1,tcp_timestamps 是用来保证是按照时间顺序来传输的。
而对于 tcp_tw_recycle 这个参数,不推荐使用,会出现数据包错乱的问题,Linux 4.12 后直接废弃了这个参数。
TCP 会缓存每个连接的最后一次时间戳(最新的),这个值在 PAWS 机制(PROTECT AGAINST WRAPPED SEQUENCE NUMBERS)迎来放置序列号环绕问题(recycle、wrapped),比如在高带宽下序列号可能就会在较短时间内重用,这样可以用这个时间戳来区分是否为合法的数据(有序),以及拒绝过期的数据(来自之前的连接的重复报文等)。也即,TCP 会拒绝四元组中 <源ip、目的端口> 的数据,在 NAT 网络下,就可能出现问题,因为多个客户端可能共用同一个出口 IP,但 timestamps 却可能不相同。这种机制的开启,取决于 tcp_tw_recycle 与 tcp_timestamps 同时开启。
被动关闭方
被动关闭方收到 FIN 后进入 CLOSE_WAIT 状态,此时连接处于半关闭状态,内核等待进程主动调用 CLOSE 关闭连接,触发 FIN 给主动关闭方。如果系统中存在大量的 CLOSE_WAIT,说明是程序出现了问题,可以从这方面入手,比如在 read == 0 后忘记调用 close 等。
被动关闭发发出 FIN 后,进入 LAST_ACK,此时如果一直没收到对方的 ACk,也会重试,策略和上面提到的主动关闭发重发 FIN 策略一致。
查看当前网络状态分布:
|
|
流程图
关闭一个 tcp 链接的流程图如下:
为什么需要四次
相同的问题来了,为什么需要 4 次挥手呢,而不是 3 、5 次?
其实本质原因与需要 3次握手 类似,因为 TCP 是一个 全双工(full-duplex)的协议,通道双方互相独立。当 client 关闭连接时,server 仍然可以在不调用 close 函数的状态下,继续发送数据,此时连接处于 半关闭状态。
1次肯定不行,client根本不确定对方是否收到了自己的FIN,直接关闭太简单粗暴,除非发送RST。2次的话,server不能保证能立即关闭,因为其可能需要继续处理、发送数据等。3次时,同理,server也不能保证client收到了自己的FIN。
所以,因为是 全双工,所以一来一回*2,最少需要4次 握手机制,才能保证一个连接正确关闭。
在 web 应用中,大多情况下,服务器才是主动关闭连接的一方,比如 nginx。这是因为 HTTP 消息是单向传输协议,服务器接收完请求才能生成响应,发送完响应后就会立刻关闭 TCP 连接,及时释放资源,才能够承载更多的用户请求。
代码示例
参考
最后,用一张图结束本文:
参考: