Linux 文件系统相关概念
基础概念
操作系统操作文件无非主要就是(通过 cpu、DMA):
- 从磁盘
load数据到内存 - 从内存写入数据到磁盘
DMA(Direct Memory Access) 意为直接内存访问。因为cpu 一个总线周期最多只能存取一次总线,且在 ARM 架构下,对于赋值等操作,不能把内存中 A 地址的值直接 copy 到 B 地址,而需要使用寄存器作为中间存储。这样一来,对于 ARM,copy 的代价需要花费两个总线周期。而有了 DMA 后,则可以直接访问内存地址而无需 cpu 参与,直接由 DMA 控制器建立源与目的传输,从而可以解放 cpu。
另外,广义上而言,内存是外存的 cache,寄存器和 cpu 多级高速缓存是内存的 cache。
内存管理
首先,放一张经典图:
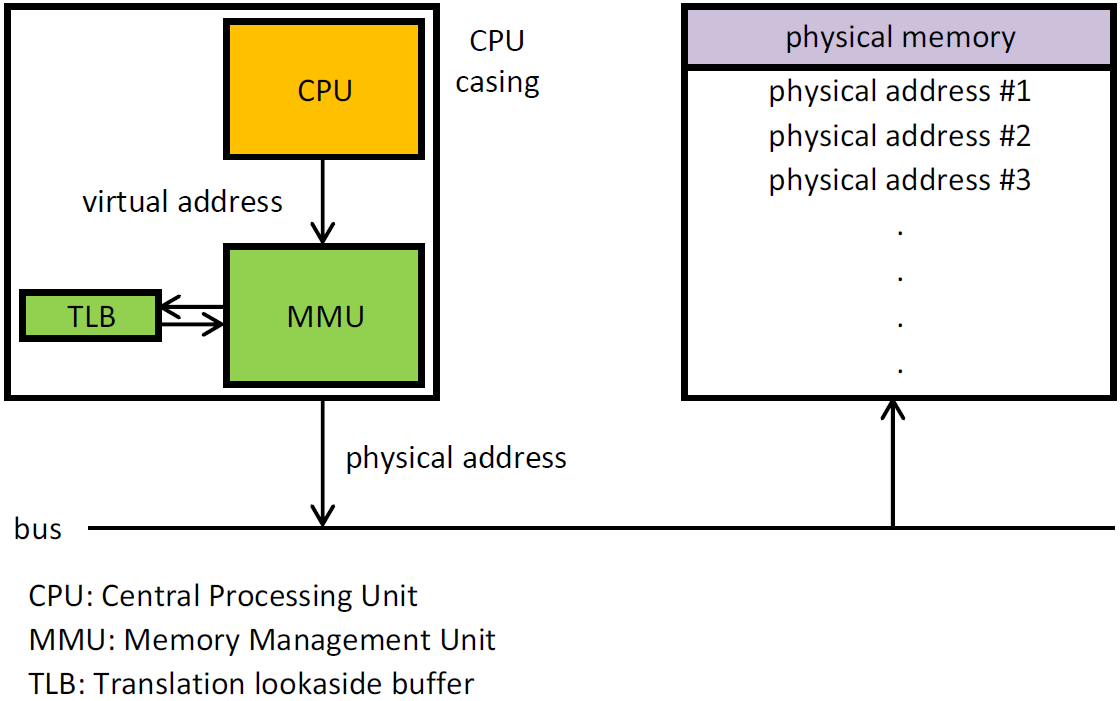
物理内存与虚拟内存
物理内存,也即我们常说的内存条,是 cpu 的地址线可以直接进行寻址的内存空间大小,常见的如 512MB、4GB、 8GB。也即,物理内存的大小,本质是 min(内存条大小, cpu 总线可寻址大小)。
从物理内存的定义即可知,其空间有限,所以不一定能满足实际中的需求,比如要读取一个大于物理内存的文件。另外,操作系统设计时,为了方便程序员编写程序,如果直接使用物理内存,多个程序可能会产生混用破坏,且所持有的空间大多是非连续的。
所以,操作系统就通过把一部分硬盘空间,当做一段连续的物理内存来使用,这就是所谓的虚拟内存,对于程序编写者来说,可以同视为一段连续的、私有的、独享的内存沙箱。
分页机制
上面提到物理内存与虚拟内存的关系,虚拟内存本质是把文件映射在物理内存中,那么操作系统是怎么管理这种映射呢?
首先,操作系统会把虚拟内存与物理内存分割成大小相同的区块,通过编号将进程的各个页离散地存储在内存中(注意:内存的地址可能不是连续的),然后以该区块大小为单位进行传输。
-
virtual page, VP:将应用程序的逻辑地址空间分割并编号,可称之为page。从进程的角度看来,它可认为自己持有一段连续的内存,进程实际运行时,可认为编号是总是从0开始的。 -
physical page, PP:对应的,也会将内存地址空间分割并编号,也即所谓的frame,是物理内存管理的单元。。
然后,操作系统有一个叫做页表(page table)的东西,本质是一个存放在物理内存中的数据结构,其中的元素成为页表项(PTE:page table entry),这些条目记录了 page 与 frame 的映射关系,形如 <page-no, frame-no>,且有如下标记位:
-
P:存在(·Present·)标志,用于指明表项对地址转换是否有效。P=1表示有效;P=0表示无效。如果无效,则会产生缺页异常,通过中断的形式装载磁盘数据至内存。 -
R/W:读/写(Read/Write)标志。其中,1表示页面可以被读、写或执行,0表示页面只读或可执行。
转换流程
我们知道,进程在运行时,其要访问的页表必须在内存中,否则就找不到数据了,所以需要实现一套转换机制。
系统会为每一个进程建立一张页表,页表在内存中起始地址与页表长度,维护在 process control block,PCB 中),进程执行时,通过查找进程自己的页表,找到每页在内存中的物理块号。页表一般通过硬件实现(页表寄存器, PTR),且常驻于内存。
大概转换流程流程如下:
- 1、进程访问某个逻辑地址(
page-no + 偏移量),触发寻址操作。 - 2、将页表起始地址、页表长度读入页表寄存器(
PTR),然后根据page-no,以及起始地址,查询页表项`。 - 3、通过页表项上的映射找到
frame-no。 - 4、通过
frame-no,加上逻辑地址的页内地址,定位到具体的物理地址(frame-no + 偏移量)。 - 5、进程访问该物理地址。
在转换流程中,会有地址保护机制,也即不能越界访问到非当前进程的地址,否则会发生段错误(Segmentation fault,SIGSEGV 信号被触发)。如果访问的页不在内存中,则会产生缺页中断,从磁盘装载数据至内存,并更新页表(按需调用)。
因为程序实际运行时,大多只需要极少的页表,所以现代操作系统常用的是多级页表机制,在单级页表上,通过增加多层级页号,如主页号、次页号等,实现按需加载。
由以上流程可知,整个过程需要访问两次内存:查找页表中的 frame-no,以及根据 frame-no 访问物理地址的数据;且多级页表需要访问多次页表数据。所以寻址的代价较大(内存速度远小于 cpu 的速度),解决方案是给 CPU 增加所谓 TLB:Translation lookaside buffer 的高速缓存,常称之为 转址旁路缓存,或称之为快表,用于缓存页表数据。有了 TLB 后,寻址流程就如下:
- 第
2步从TLB中查找页表项,找到则为命中(TLB hit):- 通过上述
3~4流程,找到具体的物理地址。 - 从
CPU的L0\L1高速缓存中查找数据,没找到再从内存中查找。
- 通过上述
- 如果
TLB不存在该页号,则等同于上述2~5流程。
一般地,上述寻址过程,是由一个叫 MMU(Memory Management Unit,内存管理单元)的硬件来实现的。
TLB 机制较为复杂,可查看这篇文深入理解:TLB原理
block、page、page cache
先来看一个现象,文件系统为 ext3:
|
|
是不是有疑问,为什么空目录、1 个字节大小的文件占据空间 4kb?为什么空文件 size=0?Blocks、IO Block 又是什么?下面就来解答下这些疑惑。
我们知道,文件都是储存在磁盘上的,磁盘的最小存储单位称之为扇区(sector),应用程序存储最小单位为字节 Byte。每个扇区储存 512B(0.5KB)。操作系统读取磁盘时,为了提高效率,不会逐个扇区读取,而是一次性连续读取多个扇区,即一次性读取一个块(block)。这种由多个扇区组成的块,是文件存取的最小单位。块 的大小,最常见的是 4KB,也即由连续八个 扇区组成。
需要搞清楚的是,sector 是磁盘的存储单位,是一个物理上的概念,属于硬件范畴;而 block 是操作系统存储文件的单位,是一个逻辑上的抽象。所以即便文件为 0,也会占用一个 block。可通过如下方式查看:
|
|
现在可以来回答上面的问题:
-
block、IO Block其实上面已经解释了,IO Block = 4096 = 8*512 -
unix哲学为一切本质都是文件,所以目录也是个文件,可以vim empty_dir,打开看到的是这个目录下的所有文件\目录(这是一个递归,哈哈)等。所以其实文件是存储在目录结构里的。 -
上面提到操作系统存储文件最小单位为
block=4096,所以在物理上会占据4kb,即便空文件或字节小于该值。 -
那么空文件,
size=0,那文件信息是保存在哪里呢?这里就涉及到另外一个重要的概念:inode,文件的元信息(创建时间、更新时间、所属组、所属用户、权限等等)都是存储在inode里,这里的size指的是文件内容大小。inode才是操作系统识别一个文件的唯一标志,而不是文件名。
那么 page 又是什么呢,其实上面已经提到了,page 常称为内存页,是操作系统用来管理内存的。其实也可以视为 virtual blocks,那么 page 与 block 关系是怎么回事呢?操作系统从磁盘读出的数据后,就保存在内存页中,当一个 block 被调入到内存,它必定要被存储在一个缓冲区中。
操作系统都会整 page 大小的读取或写入(预读机制),一般地,page 最常见的大小为 4kb。这也即是所谓的 局部性原理。
在 *nix 系统的实现中,有 buffer cache 和 page cahe,buffer cache缓存的是文件 inode、dentry 等元信息,优化磁盘 block I/O,而 page cache由多个物理上的 page 组成, 缓存的则是具体的文件内容(file 结构体定义),优化文件 I/O。
page cache 与 sync 机制
上一小节提到了 page cache,是操作系统用来 cache file 的,读取和写入都是按照 page 进行。
-
read:读取的时候,先读page cache,存在则视为hit,直接返回,不存在再从磁盘上按需加载至page cache。 -
write:写入的时候也类似,先写page cache,被修改的page称之为脏页(dirty page),维护在dirty list中,再自动或主动写回磁盘(flush),保证磁盘与内存的数据一致。自动刷盘是内核保证的,内核周期性的将dirty list的数据刷盘;主动刷盘需要调用sync函数集,详细可参考 Linux fsync和fdatasync系统调用实现分析(Ext4文件系统)。
查看自动刷盘的周期:
|
|
mmap 与 COW
mmap 是 read\wirte 外读写数据的另一种方式,使用 read\write 的流程大致如下:
- 从磁盘拷贝到
page cache; - 从
page cache拷贝到用户空间的某buffer(用户缓冲区)。
也即,这里需要两次拷贝。
而使用 mmap 机制,用户进程可以通过指针操作直接读写 page cache,这样就省去了第二次拷贝。但因为在这个过程中,可能会出现大量的缺页中断,所以性能不一定更好。
详细可参考:Linux中的mmap映射 [一]
cow 完整语义是 copy on write,也即大名鼎鼎的写时拷贝。顾名思义,当多个进程拷贝某份数据时,当且仅当有修改,才真正触发拷贝。思想类似于上面提到的页表加载机制,按需加载,内核拖得越久越好,可以极大提高吞吐量和性能。
推荐阅读
操作系统太复杂了,还涉及到硬件,这就知识盲区了